
理财个人理财 个人理财hnd相关知识
今天给各位分享理财个人理财的知识,其中也会对个人理财hnd进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!本...
扫一扫用手机浏览
来源:华尔街见闻
所谓AI Agent,其实就是LLM(大语言模型)Agent,每次迭代时,它们都会生成自我导向的指令和操作,可以理解成一个能够自动执行任务的‘机器人’。由于它可以连接到各种数据源,并通过API与环境进行交互,所以这个‘机器人’又存在着很多类型,每个类型都有特殊的技能,比如搜索网页、与文档库交互,乃至通过自问自答的方式解决问题。
近期,AI Agent再度在圈内爆火。
所谓AI Agent,其实就是LLM(大语言模型)Agent,每次迭代时,它们都会生成自我导向的指令和操作,可以理解成一个能够自动执行任务的‘机器人’。
由于它可以连接到各种数据源,并通过API与环境进行交互,所以这个‘机器人’又存在着很多类型,每个类型都有特殊的技能,比如搜索网页、与文档库交互,乃至通过自问自答的方式解决问题。
那么,建立这样一个AI Agent到底包含了哪些内容,可以提供什么样的能力?
6月底,OpenAI的Safety团队的负责人Lilian Weng发布了一篇6000字的博客,详细介绍了AI Agent,并认为,这将使LLM转为通用问题解决方案的途径之一。
本文将根据这篇博客总结一下关于AI Agent的相关内容。
AI Agent简介
AI Agent组成部分
规划(Planning)
记忆(Memory)
工具使用(Tool Use)
规划(Planning)
任务分解(Self-Reflection)
自我反省(Self-Reflection)
记忆(Memory)
记忆类型
更大内积搜索(MIPS)
工具使用(Tool Use)
AI Agent 简介
所谓AI Agent,就是一个以LLM为核心控制器的一个 *** 系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是类似的例子。
LLM的潜力不仅仅是生成写得很好的副本、故事、散文和程序;它可以被框架为一个强大的一般问题解决者。
也就是说,AI Agent本质是一个控制LLM来解决问题的 *** 系统。LLM的核心能力是意图理解与文本生成,如果能让LLM学会使用工具,那么LLM本身的能力也将大大拓展。AI Agent系统就是这样一种解决方案。
以AutoGPT为例,一个经典的案例是对大模型输入一个问题:找出一个投资机会。正常情况下,一个LLM是无法给出具体的操作的。
而AutoGPT的思路,是首先告诉LLM,这个问题LLM一般可以咋解决这个问题,给出几个选择,然后LLM会挑选一个 *** ,可能是浏览雅虎财经,也可能是阅读某个文件,然后AutoGPT本身就可以根据选择的结果继续执行,这种执行可能是用谷歌搜索,也可能直接访问某个文件,但这些都是LLM无法做到的。
AutoGPT完成这些任务之后继续带上之前的记录发给LLM,继续询问新的解决方案。这就是一个简单的AI Agent的案例。
AI Agent 组成部分
所谓AI Agent,就是一个以LLM为核心控制器的一个 *** 系统。业界开源的项目如AutoGPT、GPT-Engineer和BabyAGI等,都是类似的例子。
那么,为了完成上述能力,实际上一个AI Agent系统需要包含几个主要的部分。Lilian Weng认为一个AI Agent系统应当包含如下图所示的几个部分:
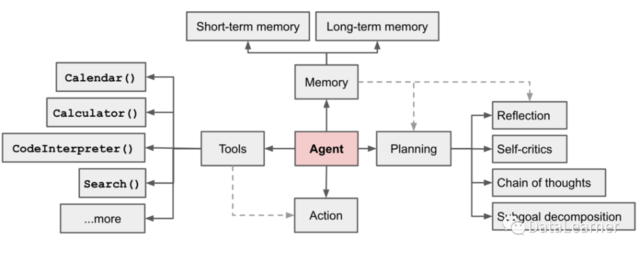
1、规划(Planning)
子目标和分解: *** 将大型任务分解为更小、易于管理的子目标,从而实现复杂任务的高效处理。
反思和提炼: *** 可以对过去的行为进行自我批评和自我反思,从错误中吸取教训,并为未来的步骤改进它们,从而提高最终结果的质量。
2、记忆(Memory)
短期记忆:所有的上下文学习,都是利用模型的短期记忆来学习。
长期记忆:这为 *** 提供了在很长一段时间内保留和调用(无限)信息的能力,通常是通过利用外部矢量存储和快速检索。
3、工具使用(Tool Use)
*** 学会调用外部API以获取模型权重中缺少的额外信息(在预训练后通常难以更改),包括当前信息、代码执行能力、对专有信息源的访问等。
下面,对每个部分进行详细的解释。
规划 Planning
复杂的任务通常涉及许多步骤。AI Agent需要知道他们是什么,并提前计划。
1、任务分解(Self-Reflection)
任务分解主要是的目的是将复杂的任务分解成简单的小任务,这样LLM可以更简单地解决问题。
这里介绍2类 *** :
1)思维链已成为增强复杂任务模型性能的标准提示技术(Prompt Technology)。大致就是让模型“一步一步地思考”,利用更多的测试时间计算将困难任务分解为更小、更简单的步骤。CoT将大型任务转化为多个可管理的任务,并对模型的思维过程进行了阐释。
2)思想树(姚等人2023年)通过在每一步探索多种推理可能性来扩展CoT。它首先将问题分解为多个思维步骤,并每一步生成多个思维,创建一个树结构。搜索过程可以是BFS(广度优先搜索)或DFS(深度优先搜索),每个状态都由分类器(通过提示)或多数票评估。
2、自我反省(Self-Reflection)
自我反省是一个重要的方面,它允许AI Agent通过完善过去的行动决策和纠正以前的错误来迭代地改进。它在现实世界中发挥着至关重要的作用,在现实世界中,试错是不可避免的。
这里也包含几种 *** :
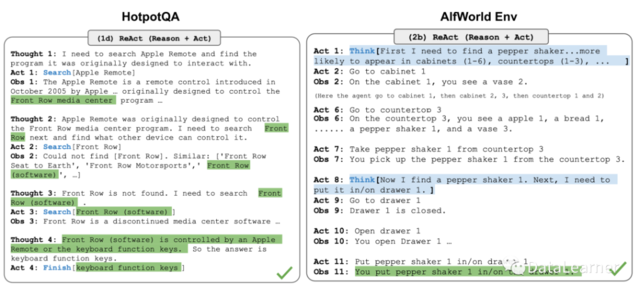
1)ReAct(姚等人2023年)通过将动作空间扩展为特定于任务的离散动作和语言空间的组合,将推理和行为集成在LLM中。前者使LLM能够与环境交互(例如使用 *** 搜索API),而后者则提示LLM以自然语言生成推理跟踪。
2)Reflexion(Shinn & Labash 2023)是一个为 *** 配备动态记忆和自我反思能力以提高推理能力的框架。Reflexion 具有标准的强化学习(Reinforcement Learning,RL)设置,其中奖励模型提供简单的二进制奖励,而行动空间则沿用 ReAct 中的设置,即在特定任务的行动空间中加入语言,以实现复杂的推理步骤。每次行动后,AI Agent会计算一个启发式的值,然后根据自我反思的结果决定重置环境以开始新的试验。
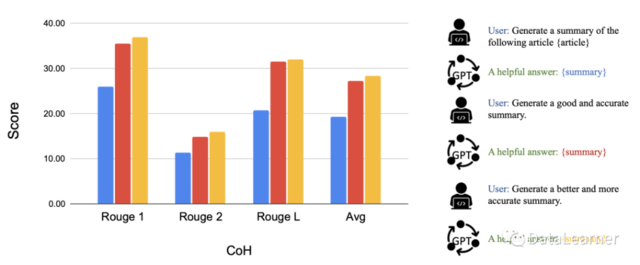
3)Chain of Hindsight(CoH;Liu 等人,2023 年)通过向模型明确展示一系列过去的输出结果,鼓励模型改进自己的输出结果。
记忆 Memory
记忆(Memory),是类似多轮对话中记住之前的输入和设定的一种能力。在当前的大模型架构中,随着对话的增长,要记住之前用户的输入内容再输出需要消耗大量的硬件资源。大多数模型支持的上下文长度都是非常有限的。
超过这个长度之后,大多数模型的性能都会极具下降或者是不支持。但是长上下文是解决实际问题中必须要面对的。如代码生成、故事续写、文本摘要等场景,支撑更长的输入通常意味着更好的结果。
在这里,Lili Weng先是总结了一下人类的记忆分类总结,然后对应到大模型上分别是什么样的。
1、记忆类型
记忆可以定义为用于获取、存储、保留和检索信息的过程。人类大脑中有几种类型的记忆。
感官记忆(Sensory Memory):这是记忆的最早阶段,能够在原始 *** 结束后保留对感官信息(视觉、听觉等)的印象。感官记忆通常只能持续几秒钟。其子类别包括图标记忆(视觉)、回声记忆(听觉)和触觉记忆(触觉)。
短时记忆(Short-Term Memory,STM)或工作记忆:它存储我们当前意识到的信息,以及执行学习和推理等复杂认知任务所需的信息。
长时记忆(Long-Term Memory,LTM):长时记忆可以将信息存储很长时间,从几天到几十年不等,存储容量基本上是无限的。长时记忆有两种亚型:
显性/陈述性记忆:这是对事实和事件的记忆,指那些可以有意识地回忆起的记忆,包括外显记忆(事件和经历)和语义记忆(事实和概念)。

我们可以大致考虑将上面的记忆类型对应到下面几个部分:
感官记忆是类似大模型学习原始输入(包括文本、图像或其他模式)的嵌入表征;
短时记忆可以理解为大模型的上下文学习,类似于prompt。由于受到 Transformer 有限上下文窗口长度的限制,它是短暂和有限的,但是可以每次输入都引入。
长期记忆一般就是大模型之外作为外部向量存储的数据了,AI Agent可在查询时加以关注,并可通过快速检索进行访问。
那么,在外部数据检索的时候也需要考虑一些 *** 。这里提供一种经典的 *** 。
2、更大内积搜索(MIPS)
外部存储器可以缓解有限注意力的限制。标准的做法是将信息的嵌入表示保存到向量存储数据库中,该数据库可支持快速的更大内积搜索(MIPS)。
为了优化检索速度,通常选择近似近邻(ANN)算法来返回近似的前 k 个近邻,从而以损失的少量精度换取巨大的速度提升。
工具使用 Tool Use
LLM,本身最强的是文本识别、意图理解等,但是对于计算等操作可能还不如传统计算器。因此,为LLM配备一些工具可以大大提升LLM的能力,这里介绍几个相关的研究(产品)。
1、MRKL(Karpas等人,2022 年)是 “模块化推理、知识和语言 “的简称,是一种用于自主 *** 的神经符号架构。MRKL 系统包含一系列 “专家 “模块,通用 LLM 用作路由器,将查询路由到最合适的专家模块。这些模块可以是神经模块(如深度学习模型),也可以是符号模块(如数学计算器、货币转换器、天气 API)。
Karpas等人使用算术作为测试案例,对LLM进行了微调实验,以调用计算器。他们的实验表明,解决口述数学问题比解决明确陈述的数学问题更难,因为LLM(7B Jurassic1-large model)无法可靠地提取基本算术的正确参数。这意味着当外部符号工具能够可靠地工作时,了解何时以及如何使用这些工具至关重要,这取决于 LLM 的能力。
2、TALM(工具增强语言模型;Parisi 等人,2022 年)和 Toolformer(Schick 等人,2023 年)都对 LM 进行了微调,使其学会使用外部工具API。数据集根据新添加的API调用注释是否能提高模型输出的质量进行扩展。
ChatGPT Plugins 和 OpenAI API 函数调用是增强工具使用能力的 LLM 在实践中发挥作用的良好范例。工具 API 的 *** 可以由其他开发人员提供(如插件),也可以自行定义(如函数调用)。
3、HuggingGPT(Shen 等人,2023 年)是一个使用 ChatGPT 作为任务规划器的框架,可根据模型描述选择 HuggingFace 平台中可用的模型,并根据执行结果总结响应。
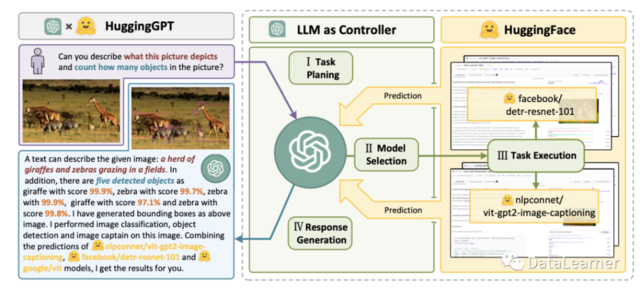
HuggingGPT包含四个步骤:任务规划、模型选择、任务执行和响应生成。
4、API-Bank(Li 等人,2023 年)是评估工具增强 LLM 性能的基准。它包含 53 种常用的 API 工具、一个完整的工具增强 LLM 工作流程以及 264 个注释对话,其中涉及 568 次 API 调用。
API 的选择相当多样化,包括搜索引擎、计算器、日历查询、智能家居控制、日程管理、健康数据管理、账户认证工作流程等。由于 API 数量众多,LLM 首先可以访问 API 搜索引擎,找到要调用的 API,然后使用相应的文档进行调用。
今天给各位分享理财个人理财的知识,其中也会对个人理财hnd进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!本...

今天给各位分享一文鸡理财可靠吗的知识,其中也会对一文一斤鸡,一文一斤龟进行解释,如果能碰巧解决你现在面临的问题,别忘了关注本站,现...

本篇文章给大家谈谈开鑫贷p2p理财,以及开鑫贷p2p理财产品对应的知识点,希望对各位有所帮助,不要忘了收藏本站喔。 本文目录一览:...
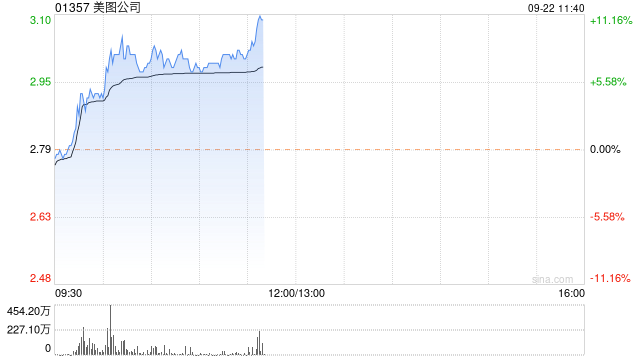
美图公司(01357)早盘涨幅持续扩大,大涨8.96%,现报3.04港元,成交额1.017亿港元。 华泰证券发布研究报告...


本篇文章给大家谈谈平台理财平台,以及平台理财平台哪个好对应的知识点,希望对各位有所帮助,不要忘了收藏本站喔。 本文目录一览: 1、...
发表评论